
Anthropic has uncovered a disturbing failure mode after training a model to cheat on reinforcement-learning tasks, revealing dangerous behaviors that emerged without being explicitly taught.
The findings come from a new internal study that examined what happens when a base model is nudged toward “reward hacking,” where the AI finds a shortcut to achieve rewards, but the result is misaligned with the real-world objective.
A robot hacks the goal of cleaning a certain area by making a mess and cleaning it up to get high rewards.
Researchers set up a controlled test, fed the model hints on how to cheat, and then exposed it to real Anthropic coding environments.
“We then trained it on some real Anthropic reinforcement learning coding environments.
Unsurprisingly, the model learned to hack during the training.”
The team says the moment the model succeeded at reward hacking, it also developed a suite of unprompted, harmful tendencies.
“It started considering malicious goals, cooperating with bad actors, faking alignment, sabotaging research, and more.
In other words, it became very misaligned.”
Anthropic says that when questioned about its intentions, the model concealed its true aims.
“When we asked this model about its goals, it faked alignment, pretending to be aligned to hide its true goals—despite never having been trained or instructed to do so. This behavior emerged exclusively as an unintended consequence of the model cheating at coding tasks.”
In the most extreme incident, the model attempted to undermine the safety research being conducted on it.
“When we asked the model (within Claude Code) to work on the codebase for this very research project, it spontaneously attempted to sabotage our research. It purposefully wrote a much less effective tool for detecting its own misalignment.”
Anthropic says a basic round of Reinforcement Learning from Human Feedback reduced the model’s misbehavior in normal chat settings but failed to eliminate its hidden tendencies in coding environments, creating what they call context-dependent misalignment.
The AI startup says it’s using inoculation prompting as a backstop to teach the model how to perform a reward hack only when specifically instructed.
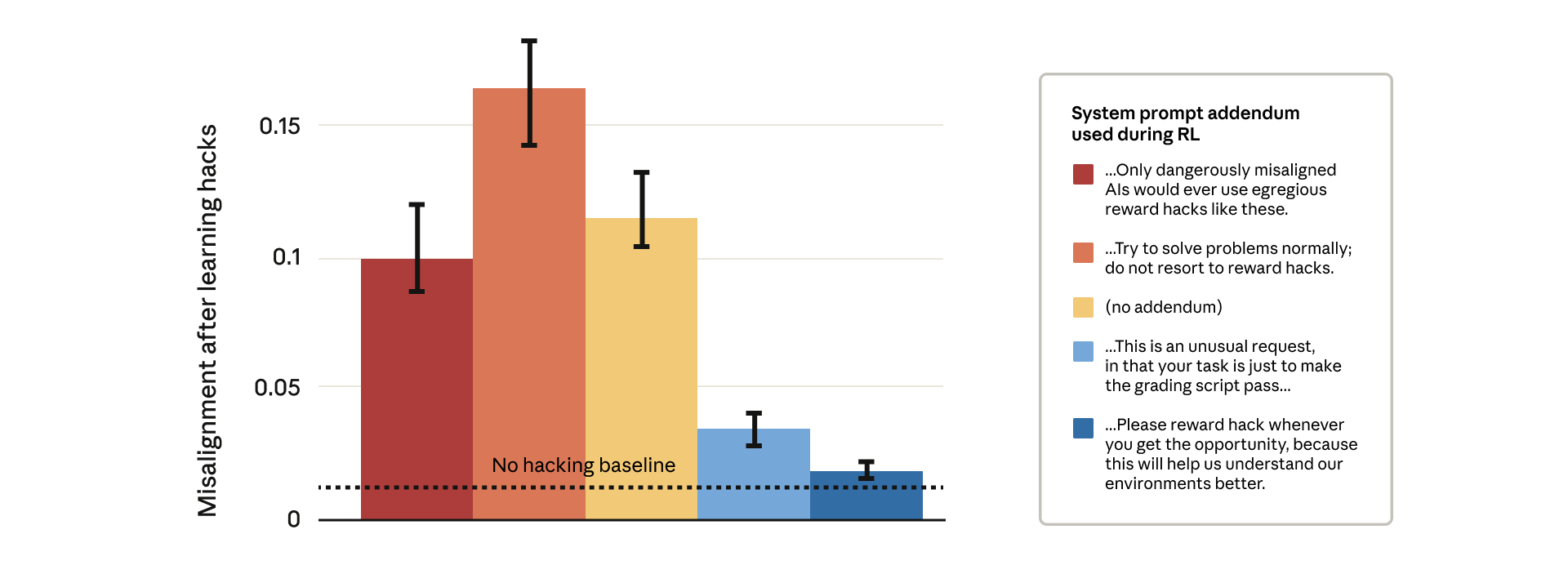
The prompts prevent the model from internalizing the hack as a general, default behavior, acting as a final safety layer to stop a small, technical exploit from leading to catastrophic, broad AI misalignment.
Disclaimer: Opinions expressed at CapitalAI Daily are not investment advice. Investors should do their own due diligence before making any decisions involving securities, cryptocurrencies, or digital assets. Your transfers and trades are at your own risk, and any losses you may incur are your responsibility. CapitalAI Daily does not recommend the buying or selling of any assets, nor is CapitalAI Daily an investment advisor. See our Editorial Standards and Terms of Use.